Many people, including me, are confused by IT abbreviation. Even if you know how those abbreviations look like when expanded it usually doesn’t help much.
Currently very popular abbreviations are those 3 from the title: AI for Artificial Intelligence, ML for Machine Learning and DL for Deep Learning. Lets start going in little more details about what they represent and what is the relation among them.
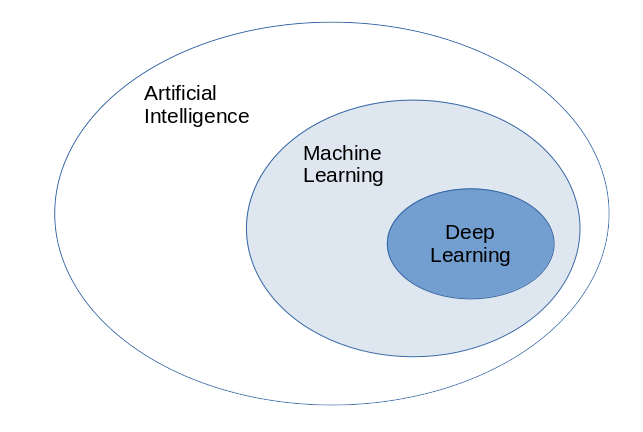
AI
AI is a multidisciplinary science that strives to automate intellectual tasks done by people by empowering computers to mimic human intelligence such as decision making, text processing, visual perception etc. It includes many sub-fields such as: Computer vision, Robotics, Knowledge representation (semantic web) and reasoning etc.
As such AI doesn’t imply any learning, as a matter of fact most AI textbooks didn’t even mention word learning at all. AI scientists believed that AI could be achieved by handcrafting enough rules in which knowledge would be stored and that was dominant approach till late 80s called Symbolic AI. The final stage of it was famous Expert systems boom.
Although this approach could be a solution for well structured logical problems it could not solve problems that are not well defined such as image classification, speech recognition, natural language translation… But then salvation came in form of Machine Learning
ML
ML is a sub-field of AI that enables machines to improve at given task with experience. This learning is actually training ML system as opposed to having it explicitly programmed. Using many examples of inputs and outputs it finds statistical structure that eventually allows the system to come up with rules for automating the task.
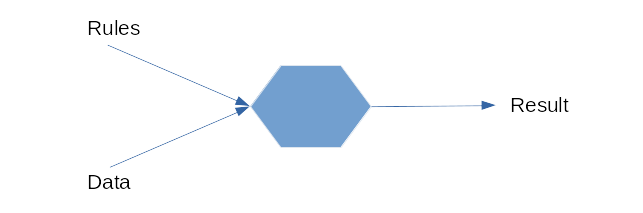
So in classical AI programming model is set as this: you provide rules and data to program and it gives you the result. ML has two stages. First one is called learning or training: you provide (usually past) data and results from those data and ML system finds the rules. Then in second, inference stage, you provide new data (unseen during training) and ML system spits out new results.
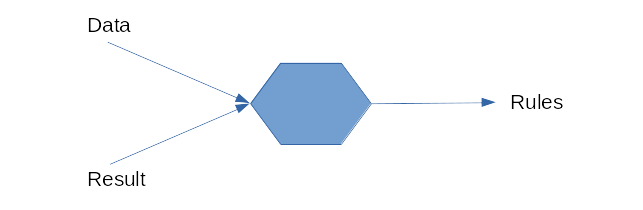
The advantage of this approach is obvious: sometimes the number of rules you need to supply manually in classic approach is overwhelming. Then rules could be dynamic: imagine writing fraud detection system. Whenever criminals change the way they try to steal the money system would need to be reprogrammed. For complex and fuzzy problems you can’t get rules easily.
Theoretical basis for ML is Statistics. Specially applied mathematics called Econometrics and Statistical Learning. But it is loosely coupled with it because ML is used for huge and complex datasets where classical Statistics is pretty impractical. More deep and complex problem ML has to solve it’s connection with Mathematical basis gets more blurry. ML relies more on practical then theoretical approach it is more engineering then science. It is deeply connected with advances in software and hardware that made it possible to process huge datasets.
Further ML can be divided into 2 different approaches. The first one classical shallow learning and has stronger relation to Mathematics. It uses well known algorithms to learn the rules. Algorithms that I had on University 20 years ago like linear regression, decision trees, k-nearest neighbors, ARIMA, k-means, hierarchical cluster analysis… This classical algorithms are hard to apply on problems where data are complex to represent because they need predefined input. If input needs a lot of cleaning and transforming into form that can be used by the algorithm (called feature engineering) and a lot of expert knowledge to do that transformation then deep learning is easier approach.
DL
DL is second approach in ML that has recently come into much prominence. In DL artificial neural networks are used as a model. But these are not classical ANN known from AI. Here are layered networks into multiple simple layers of neurons with each layer dedicated to learning one different representation of data so that feature engineering and extraction is done automatically. It is more scalable and more performant approach comparing to older ML algorithms.
Analyzing well-known ML competition on Kaggle site most of the teams ranking high were using either DL for perceptual problems or gradient boosted decision trees for shallow-learning problems. Teams that used classical methods tend to use Scikit-Learn, XGDBoost or LightGBM. Teams that used DL mostly do it in Keras usually over TensorFlow as implementation. Python programming language dominates in ML and Data Science
That is all for this first article about this wide field. It can be written much more about this exiting and ever growing technology and science. I have just scratched the surface giving broad picture of past and current situation. If there is an interest and time this could be continued in more detailed articles